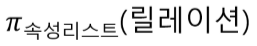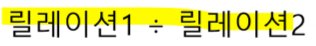relational algebra와 relational calculus는 상용화된 관계 데이터베이스에서는 실제로 사용되지 않는 개념적 언어 (** 관계 데이터에 기반한 operation을 어떻게 해야할까에 대한 대안 방법. 이론적인 측면을 토대로 만들어짐)
데이터 언어의 유용성을 검증하는 기준
relational algebra나 relational calculus로 기술할 수 있는 모든 query(질의)를 특정 데이터 언어로 기술할 수 있다면 그 언어를 relationally complete (완전)하다고 판단함 (**query(질의): 데이터에 대한 처리 요구)
관계 대수와 관계 해석
relational algebra (관계 대수)의 개념
원하는 결과를 얻기 위해 릴레이션의 처리 과정을 순서대로 기술하는 언어 (** procedual language (절차적 언어))
릴레이션을 처리하는 연산자들의 모임
대표 연산자 8개
일반 집합 연산자(set operation)와 순수 관계 연산자(relational operation)로 분류됨
closure property (폐쇄 특성)이 존재함
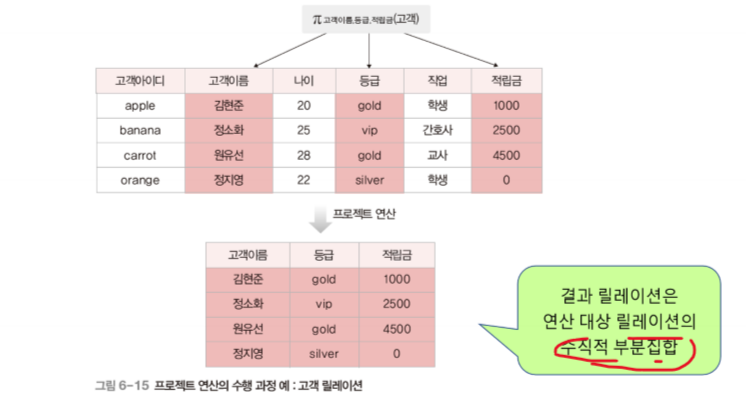
피연산자도 릴레이션이고 연산의 결과도 릴레이션임 (** 여기에서 포인트는 연산의 결과가 릴레이션이기 때문에 연산의 결과도 릴레이션이 갖는 모든 특성(튜플의 유일성, 튜플의 무순서, 속성의 무순서, 속성의 원자성(5장))을 만족해야 한다 라는 것.)
relational algebra - closure property
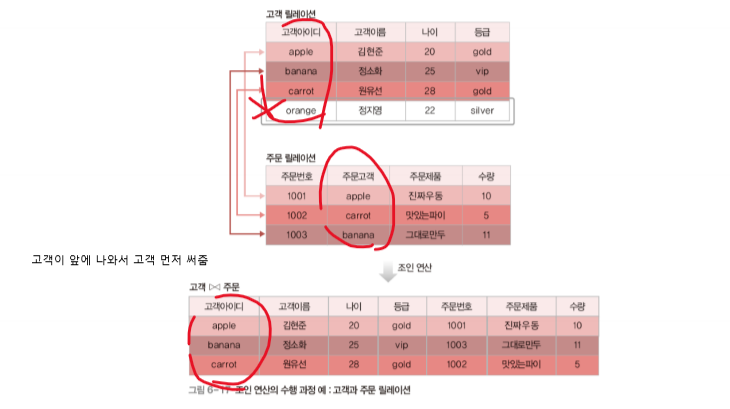
relational algebra의 operator
set operation (일반 집합 연산자)
릴레이션이 튜플의 집합이라는 개념을 이용하는 연산자
데이터베이스 분야에서는 카티션 프로덕트 라고 함
일반 집합 연산자의 특성
피연산자가 2개 필요함: 2개의 릴레이션을 대상으로 연산을 수행
합집합, 교집합, 차집합은 피연산자인 두 릴레이션이 합병 가능(union-compatible)해야 함
union-compatible (합병 가능) 조건
두 릴레이션의 degree(차수)가 같아야 함
두 릴레이션에서 서로 대응되는 속성의 도메인이 같아야 함 (** 위 두가지 조건을 만족하려면 데이터 타입이 같아야 하고, 실질적으로는 스키마가 같아야함. - 속성의 이름 정도는 다를 수 있음)
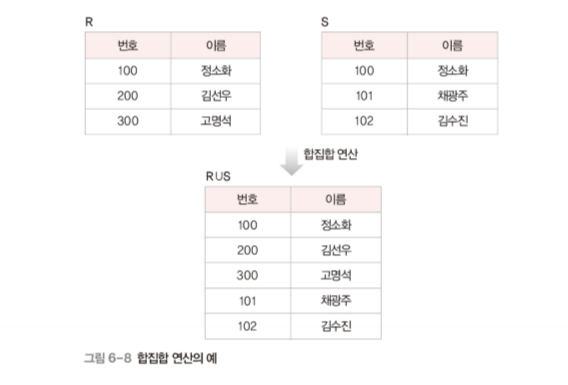
set operation - union (합집합)
합병 가능 (union-compatible) 한 두 릴레이션 R과 S의 합집합의 표기 : R∪S
릴레이션 R에 속하거나 릴레이션 S에 속하는 모든 튜플로 결과 릴레이션 구성
결과 릴레이션의 특성
degree는 릴레이션 R과 S의 degree가 같음
cardinality는 릴레이션 R과 S의 cardinality를 더한 것과 같거나 적어짐 (** 같아지는 경우: R과 S의 교집합이 없는 경우. 작아지는 경우: R과 S의 교집합이 있는 경우)
교환적 특징이 있음 (피연산자의 순서에 구애받지 않음)
R∪S = S∪R
결합적 특징이 있음 (연산 자체의 순서에도 구애를 받지 않음)
(R∪S) ∪ T = R ∪ (S∪T)
set operation - intersection (교집합)
합병 가능 (union-compatible) 한 두 릴레이션 R과 S의 교집합의 표기: R ∩ S
릴레이션 R과 S에 공통으로 속하는 튜플로 결과 릴레이션 구성
결과 릴레이션의 특성
degree는 릴레이션 R과 S의 degree와 같음
cardinality는 릴레이션 R과 S의 어떤 cardinality보다 크지 않음 (** 만약 결과 릴레이션의 cardinality가 R의 cardinaltiy와 같다라는 것은 R이 S의 부분집합이다)
교환적 특징이 있음
R ∩ S = S ∩ R
결합적 특징이 있음 (연산의 순서에 구애받지 않음)
(R ∩ S) ∩ T = R ∩ (S ∩ T)
set operation - differece (차집합)
합병 가능(union-compatible)한 두 릴레이션 R과 S의 차집합 표기: R - S = R ∩ Sc(R 교집합 S의 여집합)
릴레이션 R에는 존재하지만 릴레이션 S에는 존재하지 않는 튜플로 결과 릴레이션 구성
결과 릴레이션의 특성
degree는 릴레이션 R과 S의 degree와 같음
R - S의 cardinality는 릴레이션 R의 cardinality와 같거나 적음 (같은 경우: 교집합이 없는 경우)