SQL의 소개
- SQL (Structured Query Language)
- 의미
- 관계 데이터베이스를 위한 표준 질의어
- 비절차적 데이터 언어
- 발전 역사
- SEQUEL(Structured English QUEry Language)에서 유래
- SEQUEL: 연구용 관계 데이터베이스 관리 시스템인 SYSTEM R을 위한 언어
- 미국 표준 연구소인 ANSI와 국제 표준화 기구인 ISO에서 표준화 작업을 진행
- SEQUEL(Structured English QUEry Language)에서 유래
- 사용 방식
- 대화식 SQL: 데이터베이스 관리 시스템에 직접 접근해 질의를 작성하여 실행
- 삽입 SQL: 프로그래밍 언어로 작성된 응용 프로그램에 삽입
- 의미
- SQL의 분류
- DDL ; Data Definition Language (데이터 정의어)
: 테이블을 생성하고 변경/제거하는 기능을 제공
(** 테이블을 생성하거나 뷰를 생성하는 것에 초점. 도메인을 정의할 수도 있다. -> 스키마와 관련된 것들을 생성/변경/제거 가능) - DML ; Data Manipulation Language (데이터 조작어)
: 테이블에 새 데이터를 삽입하거나, 테이블에 저장된 데이터를 수정/삭제/검색하는 기능을 제공
(** 인스턴스나 튜플이라 부르는 실제 데이터들을 수정/삭제/검색하는 기능) - DCL ; Data Control Language (데이터 제어어)
: 보안을 위해 데이터에 대한 접근 및 사용 권한을 사용자별로 부여하거나 취소하는 기능을 제공
- DDL ; Data Definition Language (데이터 정의어)
SQL을 이용한 데이터 정의
- SQL의 데이터 정의 기능
- 테이블 생성: CREATE TABLE
- 테이블 변경: ALTER TABLE
- 테이블 생성: CREATE TABLE 문
- [ ]의 내용은 생략이 가능
- SQL 질의문은 세미콜론(;)으로 문장의 끝을 표시
- SQL 질의문은 대소문자를 구분하지 않음

- 속성의 정의
- 테이블을 구성하는 각 속성의 데이터 타입을 선택한 다음 널 값 허용 여부와 기본 값 필요 여부를 결정
- NOT NULL: 속성이 널 값을 허용하지 않음을 의미하는 키워드
(ex. 고객 아이디 VARCHAR(20) NOT NULL - DEFAULT: 속성의 기본 값을 지정하는 키워드
(ex. 적립금 INT DEFAULT 0 | 담당자 VARCHAR(10) DEFAULT '방경아' )
- 키의 정의
- ⭐ PRIMARY KEY: 기본키를 지정하는 키워드
(ex. PRIMARY KEY(고객아이디) , PRIMARY KEY(주문고객, 주문제품) -> 복합키 - UNIQUE: 대체키(alternative key를 지정하는 키워드. 대체키로 지정되는 속성의 값은 유일성을 가지며 ⭐ 기본키와 달리 널 값이 허용됨
(** UNIQUE(고객이름)) - FOREIGN KEY
- 외래키를 지정하는 키워드
- 외래키가 어떤 테이블의 무슨 속성을 참조하는지 ⭐ REFERENCES 키워드 다음에 제시
- 참조 무결성 제약조건 유지를 위해 참조되는 테이블에서 튜플 삭제 시 처리 방법을 지정하는 옵션
- ON DELETE NO ACTION: 튜플을 삭제하지 못하게 함
- ON DELETE CASCADE: 관련 튜플을 함께 삭제함
- ON DELETE SET NULL: 관련 튜플의 외래키 값을 NULL로 변경함
- ON DELETE SET DEFAULT: 관련 튜플의 외래키 값을 미리 지정한 기본 값으로 변경함
(** 생략가능. 생략한다면 DB에 따라 다르게 설정될 수 있지만, ON DELETE NO ACTION으로 설정됨)
(** 관련 튜플: 외래키를 갖고 있는 튜플)
- 참조 무결성 제약조건 유지를 위해 참조되는 테이블에서 튜플 변경 시 처리 방법을 지정하는 옵션

- ⭐ PRIMARY KEY: 기본키를 지정하는 키워드
(** intergrity constraint : 무결성 제약 조건 (5장)
- entity intergrity constraint: 개체 무결성 제약조건 - primary key 관련. 기본키 값이 null 값을 가질 수 없다.
- referential intergrity constraint: 참조 무결성 제약조건 - foreign key 관련. 외래키 값이 참조할 수 없는 값을 가질 수 없다.
)- 데이터 무결성 제약조건의 정의
- CHECK: 테이블에 정확하고 유효한 데이터를 유지하기 위해 특정 속성에 대한 제약 조건을 지정. CONSTRAINT 키워드와 함께 고유의 이름을 부여할 수도 있음
(ex. CHECK(재고량 >=0 0 AND 재고량 <= 10000) , CONSTRAINT CHK_CPY CHECK(제조업체 = '한빛제과)
- CHECK: 테이블에 정확하고 유효한 데이터를 유지하기 위해 특정 속성에 대한 제약 조건을 지정. CONSTRAINT 키워드와 함께 고유의 이름을 부여할 수도 있음
- 데이터 무결성 제약조건의 정의
- 테이블 변경: ALTER TABLE 문
- 새로운 속성 추가

- 기존 속성 삭제

- 만약, 삭제할 속성과 관련된 제약조건이 존재한다면?
- 속성 삭제가 수행되지 않음
- 관련된 제약조건을 먼저 삭제해야 함
- 만약, 삭제할 속성과 관련된 제약조건이 존재한다면?
- 새로운 제약조건의 추가

- 기존 제약조건의 삭제

- 새로운 속성 추가
- 테이블 삭제: DROP TABLE 문

- 만약, 삭제할 테이블을 참조하는 테이블이 있다면?
- 테이블 삭제가 수행되지 않음
- 관련된 외래키 제약조건을 먼저 삭제해야 함
- 만약, 삭제할 테이블을 참조하는 테이블이 있다면?
SQL을 이용한 데이터 조작
- SQL의 데이터 조작 기능:
- 데이터 검색: SELECT
- 데이터 삽입: INSERT
- 데이터 수정: UPDATE
- 데이터 삭제: DELETE
- 데이터 검색: SELECT
- 기본 검색
- SELECT 키워드와 함께 검색하고 싶은 속성의 이름을 나열
- FROM 키워드와 함께 검색하고 싶은 속성이 있는 테이블의 이름을 나열
- 검색 결과는 테이블 형태로 반환됨 (** SQL에서의 Query의 결과는 테이블의 형태)

- ALL: 결과 테이블이 튜플의 중복을 허용하도록 지정, 생략 가능
- DISTINCT: 결과 테이블이 튜플의 중복을 허용하지 않도록 지정
(** 명시하지 않으면 ALL로 적용이 되기 때문에 ALL을 사용하는 경우는 별로 없다) - AS 키워드를 이용해 결과 테이블에서 속성의 이름을 바꾸어 출력 가능
- 새로운 이름에 공백이 포함되어 있으면 큰 따옴표나 작은 따옴표로 묶어주어야 함
(오라클에서는 큰 따옴표, MS SQL 서버에서는 작은 따옴표 사용) - AS 키워드는 생략 가능
- 새로운 이름에 공백이 포함되어 있으면 큰 따옴표나 작은 따옴표로 묶어주어야 함
- 산술식을 이용한 검색
- SELECT 키워드와 함께 산술식 제시
- 산술식: 속성의 이름과 +, -, *, / 등의 산술 연산자와 상수로 구성
- 속성의 값이 실제로 변경되는 것은 아니고 결과 테이블에서만 계산된 결과값이 출력됨
- SELECT 키워드와 함께 산술식 제시
- 조건 검색
- 조건을 만족하는 데이터만 검색

- WHERE 키워드와 함께 비교 연산자와 논리 연산자를 이용한 검색 조건 제시
- 숫자뿐만 아니라 문자나 날짜 값을 비교하는 것도 가능
(ex. 'A'<'C' , '2019-12-01' < '2019-12-02' ) - 조건에서 문자나 날짜 값은 작은따옴표로 묶어서 표현

- 숫자뿐만 아니라 문자나 날짜 값을 비교하는 것도 가능
- 조건을 만족하는 데이터만 검색
- LIKE를 이용한 검색
- LIKE 키워드를 이용해 부분적으로 일치하는 데이터를 검색
- 문자열을 이용하는 조건에만 LIKE 키워드 사용 가능


- NULL을 이용한 검색
- ⭐ IS NULL 키워드를 이용해 특정 속성의 값이 널 값인지를 비교
- ⭐ IS NOT NULL 키워드를 이용해 특정 속성의 값이 널 값이 아닌지를 비교
- 검색 조건에서 널 값은 다른 값과 크기를 비교하면 결과가 모두 거짓이 됨
- 정렬 검색
- ORDER BY 키워드를 이용해 결과 테이블 내용을 사용자가 원하는 순서로 출력
- ORDER BY 키워드와 함께 정렬 기준이 되는 속성과 정렬 방식을 지정
- 오름차순(기본): ASC / 내림차순: DESC (**아무것도 입력하지 않으면 DESC)
- 널 값은 오름차순에서는 맨 마지막에 출력되고, 내림차순에서는 맨 먼저 출력됨 (**DBMS에 따라 다름)
- 여러 기준에 따라 정렬하려면 정렬 기준이 되는 속성을 차례대로 제시

- 집계 함수를 이용한 검색
- 특정 속성 값을 통계적으로 계산한 결과를 검색하기 위해 집계 함수를 이용
- 집계 함수 (aggregate function)
- 열 함수 (column function)라고도 함
- 개수, 합계, 평균, 최댓값, 최솟값의 계산 기능을 제공
- 집계 함수 (aggregate function)
- 집계 함수 사용 시 주의 사항
- 집계 함수는 널인 속성 값은 제외하고 계산함
- ⭐ 집계 함수는 WHERE 절에서는 사용할 수 없고, SELECT 절이나 HAVING 절에서만 사용 가능
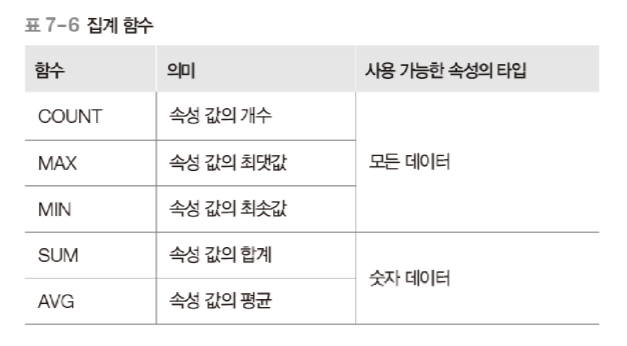
- 집계 함수는 널인 속성 값은 제외하고 계산하기 때문에 COUNT(속성)을 했을 경우, 널 값으로 인해 정확한 값을 얻을 수 없는 경우가 있음 → 정확한 개수를 계산하기 위해서는 보통 기본키 속성이나 *를 주로 이용 (ex. SELECT COUNT(*) )
- 중복을 제거하기 위해서는 기본키 속성이 아닌 이상은 DISTINCT 키워드를 붙여야 함
- 특정 속성 값을 통계적으로 계산한 결과를 검색하기 위해 집계 함수를 이용
- 그룹별 검색

- GROUP BY 키워드를 이용해 특정 속성의 값이 같은 튜플을 모아 그룹을 만들고, 그룹별로 검색
- GROUP BY 키워드와 함께 그룹을 나누는 기준이 되는 속성을 지정
- HAVING 키워드를 함께 이용해 그룹에 대한 조건을 작성 (**그룹에 대한 조건은 WHERE이 아니라 HAVING을 사용)
- GROUP BY 키워드를 이용해 특정 속성의 값이 같은 튜플을 모아 그룹을 만들고, 그룹별로 검색
- 여러 테이블에 대한 조인 검색
- 조인 검색: 여러 개의 테이블을 연결하여 데이터를 검색하는 것
(** 여기에서의 조인은 equi-join. 보통 데이터베이스에서 사용하는 조인은 equi-join) - 조인 속성: 조인 검색을 위해 테이블을 연결해주는 속성
- 연결하려는 테이블 간에 조인 속성의 이름은 달라도 되지만 도메인은 같아야 함
(** 이건 최소한의 조건이고, 실질적인 조건은 이름만 다를 뿐이지 같은 속성이어야 함) - 일반적으로 외래키를 조인 속성으로 이용함
- 연결하려는 테이블 간에 조인 속성의 이름은 달라도 되지만 도메인은 같아야 함
- FROM 절에 검색에 필요한 모든 테이블을 나열
- WHERE 절에 조인 속성의 값이 같아야 함을 의미하는 조인 조건을 제시
- 같은 이름의 속성이 서로 다른 테이블에 존재할 수 있기 때문에 속성 이름에 해당 속성이 소속된 테이블의 이름을 표시 (권장; 현업에서도 이렇게 사용 중)
(** A.PK = B.FK )
- 조인 검색: 여러 개의 테이블을 연결하여 데이터를 검색하는 것
- 기본 검색
- ⭐ 부속 질의문(sub-query)를 이용한 검색
- SELECT 문 안에 또 다른 SELECT 문을 포함하는 질의
- 상위 질의문(주 질의문): 다른 SELECT 문을 포함하는 SELECT 문
- 부속 질의문(서브 질의문): 다른 SELECT 문 안에 들어 있는 SELECT 문
- 괄호로 묶어서 작성, ORDER BY 절을 사용할 수 없음
- 단일 행 부속 질의문: 하나의 행을 결과로 반환
- 다중 행 부속 질의문: 하나 이상의 행을 결과로 반환
- 부속 질의문을 먼저 수행하고, 그 결과를 이용해 상위 질의문을 수행
- 부속 질의문과 상위 질의문을 연결하는 연산자가 필요
- 단일 행 부속 질의문은 비교 연산자(=, <, >, <=, >=, <=) 사용 가능
(** 일반적으로 subquery에서는 비교연산자를 지양) - 다중 행 부속 질의문은 비교 연산자 사용 불가

EXISTS / NOT EXISTS 는 join 속성을 WHERE 절 안에 씀
- 단일 행 부속 질의문은 비교 연산자(=, <, >, <=, >=, <=) 사용 가능
- 질의 내용은 다양하게 표현 가능하므로 사용자가 자유롭게 선택
- SELECT 문 안에 또 다른 SELECT 문을 포함하는 질의

- 데이터 삽입: INSERT 문
- 데이터 직접 삽입

- INTO 키워드와 함께 튜플을 삽입할 테이블의 이름과 속성의 이름을 나열
- 속성 리스트를 생략하면 테이블을 정의할 때 지정한 속성의 순서대로 값이 삽입됨
- VALUES 키워드와 함께 삽입할 속성 값들을 나열
- INTO 절의 속성 이름과 VALUES 절의 속성 값은 순서대로 일대일 대응되어야 함
- INTO 키워드와 함께 튜플을 삽입할 테이블의 이름과 속성의 이름을 나열
- 부속 질의문을 이용한 데이터 삽입
- SELECT 문을 이용해 다른 데이블에서 검색한 데이터를 삽입

- SELECT 문을 이용해 다른 데이블에서 검색한 데이터를 삽입
- 데이터 직접 삽입
- ⭐ 데이터 수정: UPDATE 문
- 테이블에 저장된 튜플에서 특정 속성의 값을 수정

- SET 키워드 다음에 속성 값을 어떻게 수정할 것인지를 지정
- WHERE 절에 제시된 조건을 만족하는 튜플에 대해서만 속성 값을 수정
- WHERE 절을 생략하면 테이블에 존재하는 모든 튜플을 대상으로 수정
- 테이블에 저장된 튜플에서 특정 속성의 값을 수정
- 데이터 삭제: DELETE 문
- 테이블에 저장된 데이터를 삭제
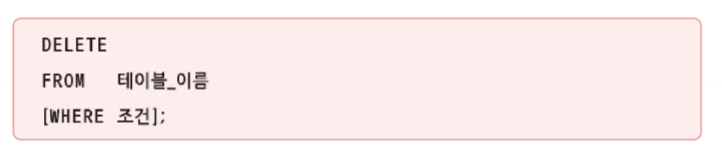
- WHERE 절에 제시한 조건을 만족하는 튜플만 삭제
- WHERE 절을 생략하면 테이블에 존재하는 모든 튜플을 삭제해 빈 테이블이 됨
- 테이블에 저장된 데이터를 삭제
뷰 (View)
(** external schema(sub schema)와 같은 개념)
- 다른 테이블을 기반으로 만들어진 ⭐가상 테이블
- 데이터를 실제로 저장하지 않고 논리적으로만 존재하는 테이블이지만, 일반 테이블과 동일한 방법으로 사용함
- 다른 뷰를 기반으로 새로운 뷰를 만드는 것도 가능함
- 뷰를 통해 기본 테이블의 내용을 쉽게 검색할 수는 있지만, 기본 테이블의 내용을 변화시키는 작업은 제한적으로 이루어짐
- 기본 테이블: 뷰를 만드는 데 기반이 되는 물리적인 테이블
- 뷰는 기본 테이블을 들여다 볼 수 있는 창의 역할을 담당
- 뷰 생성: CREATE VIEW 문

- CREATE VIEW 키워드와 함께 생성할 뷰의 이름과 뷰를 구성하는 속성의 이름을 나열
- 속성 리스트를 생략하면 SELECT 절에 나열된 속성의 이름을 그대로 사용
- AS 키워드와 함께 기본 테이블에 대한 SELECT 문 작성
- SELECT 문은 생성하려는 뷰의 정의를 표현하며 ORDER BY는 사용 불가
- WITH CHECK OPTION
- 뷰에 삽입이나 수정 연산을 할 때 SELECT 문에서 제시한 뷰의 정의 조건을 위반하면 수행되지 않도록 하는 제약조건을 지정
- CREATE VIEW 키워드와 함께 생성할 뷰의 이름과 뷰를 구성하는 속성의 이름을 나열
- 뷰 활용: SELECT 문
- 뷰는 일반 테이블과 같은 방법으로 원하는 데이터를 검색할 수 있음
- 뷰에 대한 SELECT 문이 내부적으로는 기본 테이블에 대한 SELECT 문으로 변환되어 수행
- 검색 연산은 모든 뷰에 수행 가능
- 뷰는 일반 테이블과 같은 방법으로 원하는 데이터를 검색할 수 있음
- 뷰 활용: INSERT, UPDATE, DELETE 문
- 뷰에 대한 삽입/수정/삭제 연산은 실제로 기본 테이블에 수행되므로 결과적으로는 기본 테이블이 변경됨
- 뷰에 대한 삽입/수정/삭제 연산은 제한적으로 수행됨
- 변경 가능한 뷰 vs. 변경 불가능한 뷰
- 변경 불가능한 뷰의 특징
- 기본 테이블의 기본키를 구성하는 속성이 포함되어 있지 않은 뷰
- 기본 테이블에 있던 내용이 아닌 집계 함수로 새로 계산된 내용을 포함하는 뷰
- DISTINCT 키워드를 포함하여 정의한 뷰
- GROUP BY 절을 포함하여 정의한 뷰
- 여러 개의 테이블을 조인하여 정의한 뷰는 변경이 불가능한 경우가 많음


- 뷰의 장점
- 질의문을 좀 더 쉽게 작성할 수 있다.
- GROUP BY, 집계 함수, 조인 등을 이용해 뷰를 미리 만들어 놓으면, 복잡한 SQL 문을 작성하지 않아도 SELECT 절과 FROM 절만으로도 원하는 데이터의 검색이 가능
- 데이터의 보안 유지에 도움이 된다.
- 자신에게 제공된 뷰를 통해서만 데이터에 접근하도록 권한 설정이 가능
- 데이터를 좀 더 편리하게 관리할 수 있다.
- 제공된 뷰와 관련이 없는 다른 내용에 대해 사용자가 신경 쓸 필요가 없음
(** external schema의 장점과 일치)
- 제공된 뷰와 관련이 없는 다른 내용에 대해 사용자가 신경 쓸 필요가 없음
- 질의문을 좀 더 쉽게 작성할 수 있다.
- 뷰 삭제: DROP VIEW 문
- 뷰를 삭제해도 기본 테이블은 영향을 받지 않음

- 만약, 삭제할 뷰를 참조하는 제약조건이 존재한다면?
- 예) 삭제할 뷰를 이용해 만들어진 다른 뷰가 존재하는 경우
- 뷰 삭제가 수행되지 않음
- 관련된 제약조건을 먼저 삭제해야 함
- 뷰를 삭제해도 기본 테이블은 영향을 받지 않음
'데이터베이스' 카테고리의 다른 글
| [데이터베이스론] 9장. 정규화 (0) | 2024.06.07 |
|---|---|
| [데이터베이스론] 8장. 데이터베이스 설계 (0) | 2024.06.07 |
| [데이터베이스론] 6장. 관계 데이터 연산 (0) | 2024.04.12 |
| [데이터베이스론] 5장. 관계 데이터 모델 (0) | 2024.04.11 |
| [데이터베이스론] 4장. 데이터 모델링 (0) | 2024.04.11 |



