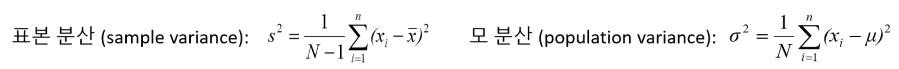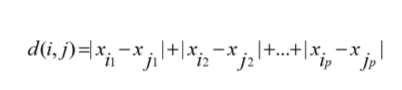attribute : 변수, field, 특성, 특징 (크게 두 가지 유형으로 분류. categorical과 numeric)
데이터 셋 (** 데이터나 데이터 셋을 요즘은 그냥 구분하지 않는다고 함)
데이터 객체들의 집합
Categorical 속성 유형
Nominal (명목형): categories, states, or "names of things"
Values are just different names (** 어떤 값 (values)이 서로 다른 이름일 뿐, 순서가 없다)
Marital status, occupation, ID numbers (treated more like symbols), zip codes
Eyes color = {brown, black, blue, green, hazel}
Binary (이진)
Nominal attribute with only 2 states (0 and 1) (** 사실 nominal과 같지만, 대부분의 데이터 분석의 목표는 decision making 인데, 이 decision이 binary한 경우가 많음 (질병이 있느냐 없느냐와 같은 것))
Symmetric binary: both outcomes not equally important (e.g., medical test (positive vs. negative) (** Symmetric은 둘 다 중요. Asymmetric은 한 쪽만 중요. 개랑 고양이 decision making도 binary한 결정이지만, 둘 다 중요하므로 symmetric. 스마트팜에서 정상이냐 비정상이냐는 이상이 들어왔을 때만 보면 되니 asymmetric. )
Convention: assigning 1 to most important outcome (e.g., HIV positive) (** 좀 더 중요한 부분에 1을 assign 하는 법. 꼭 지키지는 않아도 되지만 조금 더 의미있는 결과를 내기위해 넣는다고 함)
Ordinal (순서형)
Values have a meaningful order(ranking), but magnitude between successive values is not known
Sizes (= {small, medium, large} ), grades, army rankings
Numeric 속성 유형
Interval (** 데이터베이스의 discrete와 비슷하지만 똑같지는 않음)
Values are measured on a scale of equal-sized units; values have order
No true zero-point (e.g., 0℃ is, in a physical sense, arbitrary (** 온도가 0도인 것이지, 온도가 없는 것이 아님)
Ratio (** 실제로 재는 수량)
Inherent zero-point (e.g., length, counts, monetary quantities (** 무게가 0이라는 것은 진짜 무게가 없다는 것)
(** 데이터의 본질적인 것에 집중해야할 때 이런 것들을 사용할 수 있게 된다. 데이터 마이닝에서는 현실세계에 있는 숫자냐, 인간이 만들어낸 숫자냐 이런게.. 있다.
)
데이터 셋의 유형
데이터 셋의 유형
record data (레코드 데이터) (** 레코드 라는 것은 데이터베이스에서 배운 테이블이라고 생각하면 됨)
Data matrix (** 행렬)
Document data (** 텍스트 데이터)
Transaction or market basket data (** 거래 데이터. 거래 데이터는 계산대에 찍은 물건들이 쭉 있는게 거래 데이터. 산 물건들, 고객 정보 등이 있음)
ordered data (순서 데이터)
Sequential data or temporal data
Time-series data
Trajectory data (** 무빙 오브젝트가 있는 그래프. 스마트폰에 GPS를 키고 다니면 경로가 찍히는 것.)
graph data (그래프 데이터) (** 노드와 edge로 표현되는 데이터. 대표적인 것은 Social networks)
World Wide Web
Social networks
Molecular structures
record data (레코드 데이터) (** 행과 열이 있는 테이블 형태)
레코드들의 모임으로 구성된 데이터
각 레코드는 고정된 속성의 셋으로 구성
data matrix (데이터 행렬) (** 다차원 공간의 하나의 점으로 간주할 수 있음)
고정된 수치 속성으로 구성된 데이터 객체의 경우, 다차원 공간의 하나의 점으로 간주할 수 있음 (** 행렬에서 차원은 속성의 size가 됨. m x n 의 테이블이라면 n차원 행렬이 됨)
이러한 데이터는 m x n 행렬로 표현되며, 이때 m개의 행은 객체를, n개의 열은 속성을 의미
Document Data (문서 데이터)
각 문서는 단어 벡터 (term vector)로 표현함
문서의 각 단어는 벡터의 컴포넌트 (속성)에 대응
각 컴포넌트(속성)의 값은 해당 단어가 문서에서 몇 번 나타났는지 빈도에 해당
Transaction Data (트랜잭션 데이터) (** 연관 분석에서 사용되는 것 중 하나. 기저귀랑 맥주가 동시 구매율이 높아서 근처에 뒀더니 더 잘 팔렸다더라 등의 연관 분석.
레코드 데이터의 특별한 경우로서, 각 레코드(트랜잭션)는 아이템의 집합을 가짐
연관 규칙 분석에서 장바구니 데이터(market basket data)라고 불리기도 함 (ex. 식품점에서 한 명의 고객이 한 번에 구매한 제품들의 목록)
Graph data (그래프 데이터) (** Graph G = (V, E) 또는 Graph G = (N, L) )
Graph G = (V, E)
V = 정점(노드)의 집합 (a set of vertices, a set of nodes)
E = 엣지(링크)의 집합 (a set of edges, a set of links) (** Graph는 network라고도 함. 여기에서 network는 통신의 의미가 아닌, graph의 의미. graph는 수학적인 의미. 네트워크는 실제적인 시스템의 의미) (** Graph G = (V, E) 라는 것은 그래프 Gk는 vertax의 set과 edge의 set으로 구성되어진다. 링크에 방향이 있는 그래프를 directed graph라고 한다. (반대말은 undirected graph) directed graph는 인스타그램, undirected graph는 페이스북. (간선의 방향성에 따름) 링크에 가중치를 줄 수도 있음. 이렇게 가중치를 줄 수 있는 그래프가 weighted graph (<-> unweigthed graph)
World Wide Web (월드 와이드 웹)
웹 페이지 간의 HTML 링크는 그래프 데이터로 표현이 가능함 (** 그래프 데이터의 예로 사용되는 것. 하이퍼 링크가 있는 경우에 서로 relation이 있다. 이런 걸 그래프로 나타낼 수가 있다. 슈퍼 인싸: 구글)
Social Network (소셜 네트워크 데이터)
SNS 상에서의 유저들 간 관계를 그래프 데이터로 모델링 가능함
Six degree of separation: the idea that everyone is on average approximately six steps away from any other steps away from any other person on Earth, so that of chain of, "a freind of a friend" statements can be made, on average, to connect any two people in six steps or fewer (** Graph neural net. Six degree of seperation: 지구상의 모든 사람들이 인스타를 하고 실제 relationship을 투영해놨다고 가정을 하면, 전세계의 모든 사람이 여섯단계만 거치면 친구가 될 수 있다.)
Molecular structures (분자 구조)
화합물은 기본적으로 그래프 데이터 구조로 표현됨
Ordered Data (순서 데이터)
Sequential Data (순차적 데이터)
sequences of transactions (트랜잭션들의 시퀀스)
Time-Series Data (시계열 데이터)
일정한 시간 간격으로 연속적으로 측정되는 데이터 포인트들의 시퀀스
Trajectory Data (궤적 데이터)
움직이는 물체(moving object)의 위치 및 타입 스탬프의 시퀀스 (** 거북이가 어떻게 움직이는지, 기상청에서 태풍이나 허리케인들의 궤적을 수집해서 분석을 통해 미래 경로를 예측하는 것을 함)
데이터를 표현하는 기본 통계
Central Tendency (중심 경향) 측정
Mean (평균값)
Median (중앙값)
The middle value of the ordered set if the number of data is odd; otherwise, the average of the two middle values (** 정렬해서 중앙값 보는 게 좋긴 하지만, 대용량의 데이터일 경우에는 평균값을 보는 경우가 많음)
Mode (최빈값)
The value that occurs most frequently in the set
Unimodal: only one mode 6 in [1, 3, 6, 6, 6, 6, 7, 7, 12, 12, 17]
Outlier: usually, a value higher/lower than 1.5 x IQR
분산과 표준편차
분산
표준편차: 분산의 제곱근
데이터 가시화
데이터 가시화 (visualization)의 목적
To gain insight into an information space by mapping data onto graphical primitives
To provide qualitative overview of large data sets
To search for patterns, trends, structure, irregularities, relationships among data
To help find interesting regions and suitable parameters for further quantitative analysis
To provide a visual proof of computer representations derived (** 데이터를 시각화 시킨다. 얼마나 데이터를 직관적으로 효율적으로 보여줄 수 있는지 단순하게 데이터를 visualization을 하는 것만으로도 쉽게 볼 수 있다.) (** qualitative: 질적인)
데이터 가시화 종류
Statistical graphics (통계 그래픽)
Box plots, histograms, scatter plots, and so on (** Box plots: box plot은 quatile를 visualization할 때 사용한다. 박스에 들어가는 range가 inter-qualtile range임. 왜 Box plot이 좋은가? -> A라는 알고리즘을 만들었을 때, 원래 있던 B 알고리즘보다 A가 더 우수하다는 걸 알리고 싶음. A는 박스가 작고 B가 박스가 크고, 중앙값은 95로 같을 때, 편차가 적어서 A알고리즘이 더 안정적이라는 것을 알 수 있음.
histogram같은 경우에는 구간의 통계값. 막대그래프와는 다르다는 것을 알기.
Scatter plot 은 일반적으로 2차원으로 표현한다. x축과 y축으로 데이터를 표현하고, x축에 해당하는 속성과 y축에 해당하는 속성의 관계를 파악할 수 있다. 차원이 아무리 커진다고 해도 2차원에 투영한다. 차원축소. Feature selection과 Feature extraction이 있다. )
Thematic cartography (주제별 지도)
A type of map or chart especially designed to show a particular theme connected with a specific geographic area (ex. choropleth) (** 통계 그래픽보다는 안 쓰임. 컬러코딩. HCI적 요소가 많음. 코딩을 너무 많이 사용하면 안 됨. 다양한 정보를 입히려고 모든 정보를 넣으면 보는 입장에서 역효과가 날 수 있으니 필요한 것만 넣도록 한다.
유사도와 비유사도
Similarity (유사도)
두 객체가 얼마나 닮았는지를 나타내는 수치(측정) 값
두 객체의 닮은 정도가 높을수록 높은 유사도를 가짐
Dissimilarity (비유사도)
두 객체가 얼마나 다른지를 나타내는 수치(측정) 값
두 객체의 닮은 정도가 높을수록 낮은 비유사도를 가짐 (** 비유사도는 결국 distance (거리) 라고 할 수 있다.) (** 유사도와 비유사도 보다는 유사도와 거리라고 나타낸다. (유사도도 결국 거리이기는 함.) 거리를 얼마나 정확하게, 빠르게 정하느냐가 알고리즘에서 중요하다.)
Minkowski Distance (민코우스키 거리)
민코우스키 거리의 특별한 경우
h = 1: Manhattan distance
h = 2: Euclidean distance
(** 표준은 euclidian, 많이 쓰이는 건 manhattan)