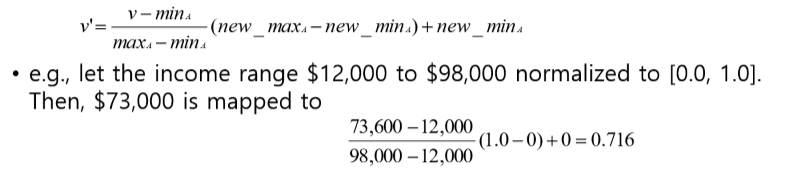데이터 전처리에 대부분의 조직들이 많은 시간과 노력을 소비함 (** 인공지능 알고리즘에서 필요한 것 -> 많고 정확한 데이터. 아무리 좋은 알고리즘이더라도 양질의 데이터가 없으면 성능이 좋지 못할 수 있음) (** model centreic AI -> Data centric AI : Labeling된 data의 중요성이 높아짐)
데이터 품질 (data quality)
다양한 측면의 데이터 품질이 존재
Accuracy (정확도): correct or wrong, accurate or not
Completeness (완전성): not recorded, unavailable, ... (** 테이블에 비는 곳이 생김 -> 커뮤니케이션 과정에서 누락될 수도 있고, 개인정보 보호 차원에서 빠져있을 수도 있음)
Consistency (일관성): some modified but some not, dangling, ... (** 정확성이 떨어진다고 볼 수 있음)
Timeliness (적시성): timely updated (** timestamp. 시기마다 달라질 수 있음)
Believability (신뢰성): trustable
Interpretability (해석가능성): easily understandable (** 데이터 자체 해석가능. visualization 해석가능한(explainable) AI, ML 분석하는 데 많이 쓰이는 용어)
데이터 전처리의 주요 형태
데이터 클리닝 (Data cleaning)
실세계 데이터는 오염되어있음 (Data in the real world is dirty)
Incomplete (불완전한): lacking attribute values, lacking certain attributes of interest, or containing only aggregate data (** 결측데이터, 누락데이터, missing data) (** e.g., Occupation = " " (missing data)
Noisy (노이지): containing noise, errors, or outliers (** e.g., Salary = "-10" (an error)) (** 잘못된 데이터)
Inconsistent (일관성이 없는): containing discrepancies in codes or names
Age = "42", Birthday = "03/07/2010"
Was rating "1, 2, 3", now rating "A, B, C"
Discrepancy between duplicate records (** data intergration을 할 때 빈번하게 발생. 표현이나 형태에 대한 일관성)
Missing data (누락 데이터)
데이터가 항상 완벽하게 채워져 있는 것은 아님
즉, 튜플에서 특정 속성에 대한 값이 없는 경우가 빈번함
누락 데이터의 발생 원인
장비가 오작동을 일으키는 경우 (** 기술적 결함)
정보가 수집되지 않는 경우 (** 의도적으로 누락된 데이터)
어떤 사람들은 개인의 나이나 몸무게와 같은 개인 정보가 수집되는 것을 거부함
때때로 속성의 값을 얻을 수 없는 경우가 존재함
연간 수입은 미성년자들에게 해당되지 않을 수 있음
누락 데이터는 추론 등의 방법으로 처리가 필요함
missing data 처리 방법
해당 튜플을 무시
classification (분류)문제에서 클래스 레이블이 없는 경우나 누락 값으로 인해 해당 튜플의 가치는 정보의 영향력이 낮다고 판단되는 경우 많이 사용됨
누락 값들을 수동으로 입력
자동으로 누락 데이터 값을 입력
전역 상수(global constant)를 이용: 예, "unknown" or ∞
속성 값들의 평균을 적용
같은 클래스에 속하는 샘플들의 속성 값들의 평균을 적용 -> smarter
베이지안 공식 또는 의사 결정 트리와 같은 추론 기반 (ex. the annual salary of a person can be infferred using his occupation and age
Noisy Data (노이즈 데이터)
Noise is a random error or variance in a measured variable (노이즈란 측정된 변수의 랜덤 에러 또는 분산이라고 할 수 있음)
잘못된 속성값의 원인: 데이터 수집 기기의 오작동, 데이터 전송 상의 문제, 기술적 한계
노이즈 데이터 처리 방법
Binning (비닝)
정렬된 데이터 값들을 몇개의 빈으로 분할하여 평활화(smoothing)하는 방법
평균치 평활화, 중앙치 평활화, 경계치 평활화 등이 있음
Regression (회귀): Fitting the data into regression functions
Clustering (클러스터링): Detecting and removing outliers
Combined computer and human inspection ;; Detecting suspicious values and checking by human (** suspicious: 의심스러운) (** 노이즈 데이터 처리하는 가장 쉬운 방법은 group화 후에 대푯값을 정해 가장 동 떨어진 애들은 버리는 형식이다.)
데이터 통합 (Data Intergration)
데이터 통합이란 다양한 소스의 데이터를 일관성있게 데이터 저장소에 결합하는 것
데이터 통합 시 스키마 통합(schema intergration), 엔티티 확인(entity resolution), 중복성(duplication), 불일치(inconsistency) 등 여러 가지 문제가 발생할 수 있음
Schema intergration (스키마 통합): 서로 다른 스키마를 갖는 여러 소스의 데이터를 통합하는 문제
⭐ Entity resolution (엔티티 확인): 다양한 소스에서 매칭되는 레코드를 찾는 문제 (ex. 만 41세와 42살과 1992년생이 모두 같은 의미인 것)
Redundancy (중복성)
Inconsistency (불일치): 같은 속성에 대해 여러 개의 값이 존재하는 경우 진짜 참 값을 찾는 문제 (ex. The price of a book might vary at different stores)
데이터 통합에서 중복 처리
여러 데이터베이스를 통합할 때 데이터 중복의 문제가 많이 발생함
객체 식별(Object identification): 동일한 속성 또는 객체가 서로 다른 데이터베이스에서 다른 이름을 가질 수 있음
유도 가능한 데이터(Derivable data): 특정 속성은 다른 테이블에서 유도된 속성 일 수 있음 (ex. annual revenue)
중복 속성은 상관 분석(correlation analysis) 및 공분산 분석(covariance analysis)으로 감지 될 수 있음
카이제곱 테스트
피어슨 상관 계수
공분산
피어슨 상관 계수 (Pearson Correlation Coefficient)
두 변수 X와 Y 사이의 상관(선형 의존성) 측정
+1과 -1 사이의 값 제공
두 변수 사이의 선형 의존성 정도의 척도로서 널리 사용됨
두 변수의 공분산을 표준 편차의 곱으로 나눈 값으로 정의
Population
Sample
-1: 완벽한 음의 상관 관계. 0: 선형 상관 관계 없음. +1: 완벽한 양의 상관 관계
⭐ 데이터 축소 (Data Reduction)
데이터베이스(database) 또는 데이터 웨어하우스(data warehouse)는 페타 바이트 단위의 데이터를 저장할 수 있으며 전체 데이터 세트에서 실행하는 복잡한 데이터 분석은 많은 시간이 걸릴 수 있음
데이터 축소 (data reduction)는 크기가 훨씬 작지만 동일한 (또는 거의 동일한) 분석 결과를 도출할 수 있는 축소된 데이터 셋을 얻는 것을 의미함
데이터 축소 전략
Dimensionality reduction (차원 축소) (** compression이 아니라 summerization을 의미함. column (attribute) 수를 줄이겠다.) (Wavelet transform, Principal components analysis(PCA), Feature subset selection, feature creation)
Numerosity reduction (숫자 감소) 또는 data reduction (데이터 감소) (** instance 를 줄이겠다) (Regression, Histograms, clustering, sampling, Data cube aggregation
Data compression (데이터 압축) (** 압축은 동일한 결과를 가져와야 함)
데이터 축소의 동기
Curse of dimensionality (차원의 저주)
차원이 증가하면 공간 상에서 데이터의 분포가 점점 희박해지는 것 (** Sperse)
클러스터링이나 이상 감지 등 데이터 분석에서 중요하게 사용되는 데이터의 밀도나 데이터 간 거리(유사도와 distance) 등이 가지는 의미가 퇴색되는 현상이 발생
데이터 축소 1: 차원 축소(Dimensionality Reduction) (** dimensionally reduction은 개체를 줄이는 게 아니라 column을 줄이는 것.)
목적
차원의 저주를 피하기 위해
데이터 분석 알고리즘이 필요로 하는 시간과 메모리를 줄이기 위해 (** 효율성)
데이터를 보다 쉽게 시각화 하기 위해
관련 없는 속성이나 노이즈를 제거하기 위해
기법
feature selection: feature의 부분집합을 뽑는 것. 내가 달성하고자 하는 목표 정답과 뭐가 가까운지. 정답을 뽑기위해서 더 영향력이 큰 것의 부분집합을 취하겠다.
feature extraction: feature를 다 쓰되, 새로운 feature(new feature) 2개를 만드는 것. 모든 feature를 다 포함하고 있는 새로운 feature를 추출하는 것임. (몇 개의 feature를 추출할 것인지는 선택) feature extraction에서 많이 쓰이는 것은 PCA(Principal Component Analysis)
데이터 축소 2: 수치 감소(Numerosity Reduction) (** instance를 줄이겠다는 것)
보다 작은 또는 간단한 데이터 표현의 형태를 선택함으로써 데이터의 크기를 축소
Parametric methods (모수적 기법)
데이터가 특정 모델에 적합하다고 가정하고 모델의 파라미터를 추정하며 모델이 맞지 않는 데이터를 제거 (ex. linear regression(선형 회귀) Y = wX + b)
Non-parametric methods (비모수적 기법)
특정 모델을 가정하지 않기 때문에 일반적으로 데이터가 정상 분포에서 벗어나거나 동변량이 아닌 경우, 유리한 측면이 있음 (ex. 히스토그램(histogram), 클러스터링(clustering), 샘플링(Sampling) 등
데이터 축소 3: 데이터 압축(Data Compression)
데이터 압축은 원래의 표현보다 적은 비트를 사용하여 정보를 인코딩 하는 프로세스를 의미함
본래 데이터의 크기를 줄이기 위해 개발되었지만 쿼리 성능 향상을 위해 많이 사용되고 있음
예를 들어 연산이 압축 데이터에 직접적으로 적용될 수 있다면 디스크 입출력(disk I/O)의 양이 훨씬 줄어들 수 있음
대부분의 데이터 웨어하우징 시스템은 데이터를 로딩할 때 데이터를 압축함
데이터 변환 및 이산화
데이터 변환 (Data Transformation)
정의
주어진 속성의 전체 값의 집합을 새로운 대체 값의 집합에 매핑하여 이전의 각 값을 새로운 값 중 하나로 식별할 수 있게 하는 함수
방법
정규화
Min-max normalization
z-score normalization
...
이산화
...
Normalization (정규화) (** 데이터를 받았는데 정규화가 안 되어있다면 정규화를 하는 게 좋음)
Min-max normalization: [new_minA, new_maxA]
Z-score normalization
데이터 이산화 (Data Discretization)
정의
속성의 범위를 간격으로 분할하여 나누고 실제 데이터 값을 간격 레이블 값으로 대체하여 연속하는 속성의 값들의 숫자를 줄이는 것
목적
데이터에서 유용한 컷 오프 포인트를 찾기 위해 (e.g., finding that the cut-off for blood's acidity is 7.3 may something to physicians
일부 학습 알고리즘을 사용하기 위해
데이터 크기를 줄이기 위해
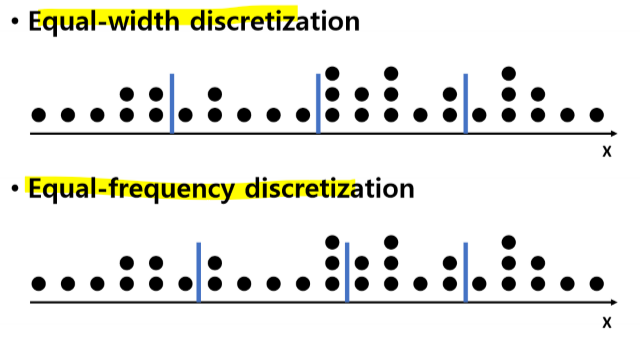
데이터 이산화의 예
Equal-width discretization (** 동일한 구간으로 나눈 것)
Equal-frequency discretization (** 구간이 아니라 frequency를 동일하게 나눈 것)