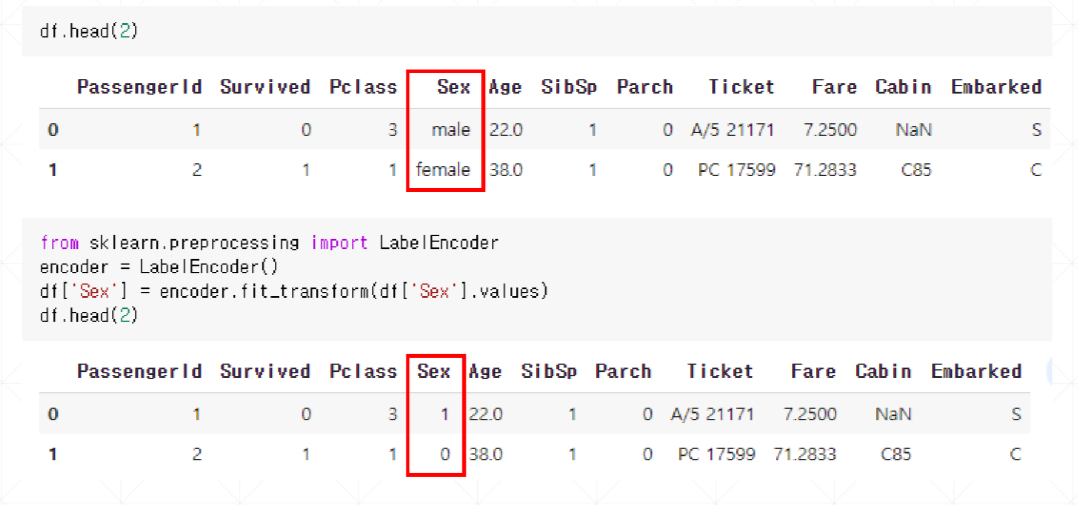
차원축소를 해야하는 가장 큰 이유는 차원의 저주(course of dimensionality) 때문이다. 차원의 저주란 데이터 학습을 위한 차원(특성)이 증가하면서 모델의 성능이 떨어지는 현상을 말한다.
차원 축소의 종류
특성 선택
특성 추출
특성 선택
Feature Selection(특성선택)은 데이터셋에서 유의미한 특성을 선택하는 과정이다. 학습에 악영향을 미치는 불필요한 특성을 제거하여 모델의 복잡성을 감소시켜, 과적합 방지와 모델성능 향상의 효과가 있다. (** feature의 부분집합을 뽑는 것. 내가 달성하고자 하는 목표 정답과 뭐가 가까운지. 정답을 뽑기위해서 더 영향력이 큰 것의 부분집합을 취하겠다. )
대표적인 특성 선택의 종류
해당 도메인의 지식을 이용
피어슨 상관계수(Pearson correlation)
랜덤 포레스트 특성 중요도(Random Forest Feature Importance)
Lasso
피어슨 상관계수
피어슨 상관계수는 두 변수 간 선형적인 상관관계의 정도를 나타내는 지표이다.
-1 ~ 1의 값을 가지며 절댓값이 클수록 높은 상관관계를 0에 가까울수록 낮은 상관관계를 나타낸다.
df = df_drop_row #df_fill, df_drop_column도 가능
df.corr()['Survived'].abs().plot.bar()
랜덤 포레스트 특성 중요도
Random Forest의 Feature Importance는 각 feature의 기여도를 나타내는 지표이다.
Feature Importance가 높은 feature일수록 예측 모델에 중요한 역할을 한다고 해석할 수 있다.
Lasso 모델에서는 L1 규제를 사용하기 때문에, 일부 feature의 계수를 0으로 만들어 해당 feature를 모델에서 제외시키는 효과가 있다.
따라서 계수가 0이 아닌 feature일수록 해당 모델에 기여한 정도가 크다고 해석할 수 있다.
from sklearn.linear_model import Lasso
import matplotlib.pyplot as plt
df_x = df.drop(['Survived'], axis = 1)
df_y = df['Survived']
lasso_model = Lasso(alpha=0.1) # alpha는 규제 강도를 설정하는 매개변수입니다.
lasso_model.fit(df_x, df_y)
# 학습된 모델을 사용하여 예측을 수행합니다.
y_pred = lasso_model.predict(df_x)
# 학습된 모델의 feature importance를 확인합니다.
importance = lasso_model.coef_
plt.figure(figsize=(8, 3))
plt.bar(df_x.columns, importance)
특성추출
Feature Extraction(특성 추출)은 데이터에서 의미 있는 정보를 추출하여 새로운 feature를 생성하는 과정이다. Feature Extraction은 특히 고차원 데이터에서 유용한다. (** feature를 다 쓰되, 새로운 feature(new feature) 2개를 만드는 것. 모든 feature를 다 포함하고 있는 새로운 feature를 추출하는 것임. (몇 개의 feature를 추출할 것인지는 선택) feature extraction에서 많이 쓰이는 것은 PCA(Principal Component Analysis) )
대표적인 특성 추출 종류
PCA(주성분 분석)
LDA(선형 판별 분석)
PCA
주어진 데이터의 주요한 정보를 나타내는 새로운 feature를 추출하여 차원을 축소한다.
이러한 feature를 주성분이라고 하며, PCA를 통해 데이터를 잘 표현하는 k개의 주성분을 추출하여 데이터를 k차원으로 축소할 수 있다.
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
df_x = df.drop(['Survived'], axis=1)
pca = PCA()
# variance ratio 계산
pca.fit(df_x)
variance_ratio = pca.explained_variance_ratio_
# elbow 그래프 그리기
plt.figure(figsize=(8, 3))
plt.plot(range(1, len(variance_ratio)+1), variance_ratio, marker='o')
plt.xlabel('Number of Components')
plt.ylabel('Variance Ratio')
plt.title('PCA Elbow Graph')
plt.show()
LDA
분류 문제에서 차원 축소를 위해 사용되는 방법으로, PCA와는 달리 클래스 간 분산과 클래스 내 분산을 모두 고려한다.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
# 예시 데이터 로드
df_x = df.drop(['Survived'], axis=1)
#LDA 모델 생성 및 variance ratio 계산
lda = LinearDiscriminantAnalysis()
lda.fit(df_x, df_y)
print('LDA설명률 : ',lda.explained_variance_ratio_)
df_x = lda.transform(df_x)
피처 스케일링
피처 스케일링
특성(feature)들의 값을 일정한 수준으로 맞춰주는 것이 피처 스케일링이라 불린다. 특성마다 분산, 범위 등 다양한 통계학적 특성이 다르기 때문에, 각 특성을 비교 분석하기가 힘들고 학습에 악영향을 준다.
피처 스케일링의 종류
표준화: 표준화의 목적은 데이터셋의 numerical value의 범위를 파라미터로 설정한 평균과 분산이 되도록 하는 방법이다.
정규화: 정규화의 목적은 데이터셋의 numerical value 범위를 사용자가 설정한 공통 척도로 변경하는 것이다.