Grocery Data Set
- Grocery Data Set 개요
- 10개의 아이템
- Shopping bags, milk, vegetables, bread, soda, yogurt, water, tropical fruit, sausage, pastry
- 100개의 트랜잭션

- 10개의 아이템
- 데이터 로딩
- read.transaction()
- arules 패키지 내에서 데이터는 트랜잭션으로 처리
- 파일로부터 트랜잭션 형태로 데이터를 로딩하는 함수
- inspect(): 트랜잭션 데이터의 내용을 출력하는 함수
groceries <- read.transactions(file = "groceries.csv", format = "basket", sep=",") inspect(groceries)
- read.transaction()
- 연관 분석 실행
- apriori(): apriori 알고리즘이 구현되어 있는 함수
- default parameters: minsup = 0.1, minconf = 0.8
rules.all <- apriori(groceries) rules.all
- default parameters: minsup = 0.1, minconf = 0.8
- 발견된 모든 rule들을 출력
inspect(rules.all)
- apriori(): apriori 알고리즘이 구현되어 있는 함수
- 룰의 정제
- 발견된 규칙 중, 의미가 없는 결과들이 많이 포함됨
- lhs (left-hands side) 값이 없는 규칙들
- minlen = 2 로 설정 (** minlen은 최소 물품 수. lhs + rhs)
- 흥미가 떨어지는 규칙들
- supp = 0.3, conf = 0.9로 설정
- lhs (left-hands side) 값이 없는 규칙들
- 출력이 너무 많아 확인이 어려운 문제
- 진행 과정 정보를 생략
- verbose = F로 설정
rules <- apriori(groceries, control = list(verbose=F), parameter = list(minlen=2, supp=0.3, conf=0.9)) rules
- verbose = F로 설정
- 진행 과정 정보를 생략
- 결과의 정렬
- quality(): apriori()의 결과에서 measure를 추출하는 함수
- round(): 실수 데이터를 digits크기의 자리에서 반올림하는 함수
- sort(): 데이터를 by 기준으로 정렬하는 함수
quality(rules) <- round(quality(rules), digits=3) rules.sorted <- sort(rules, by="confidence") inspect(rules.sorted)
- 결과 분석
- supp = 0.3, conf = 0.9 일 때, 47개의 규칙을 발견
- 하지만 모든 규칙의 rhs는 shopping bags로 나타남
- 이는 shopping bags가 대부분의 트랜잭션에서 나타나기 때문임
- Confidence의 한계점과 연관됨
- 따라서 lift를 중심으로 마이닝
- Parameter를 supp=0.2, conf=0.8로 설정
rules <- apriori(groceries, control = list(verbose=F), parameter = list(minlen=2, supp=0.2, conf=0.8)) rules quality(rules) <- round(quality(rules), digits=2) rules.sorted <- sort(rules, by="lift") inspect(rules.sorted)
- Parameter를 supp=0.2, conf=0.8로 설정
- supp = 0.3, conf = 0.9 일 때, 47개의 규칙을 발견
- 특정 데이터를 제외한 연관 규칙 마이닝
- shopping bags는 다른 데이터와 독립적이므로 연관규칙에서 제외
- none = "shopping bags"로 설정
rules <- apriori(groceries, control = list(verbose=F), parameter = list(minlen=2, supp=0.1, conf=0.8), appearance = list(none="shopping bags")) rules quality(rules) <- round(quality(rules), digits=3) rules.sorted <- sort(rules, by="lift") inspect(rules.sorted)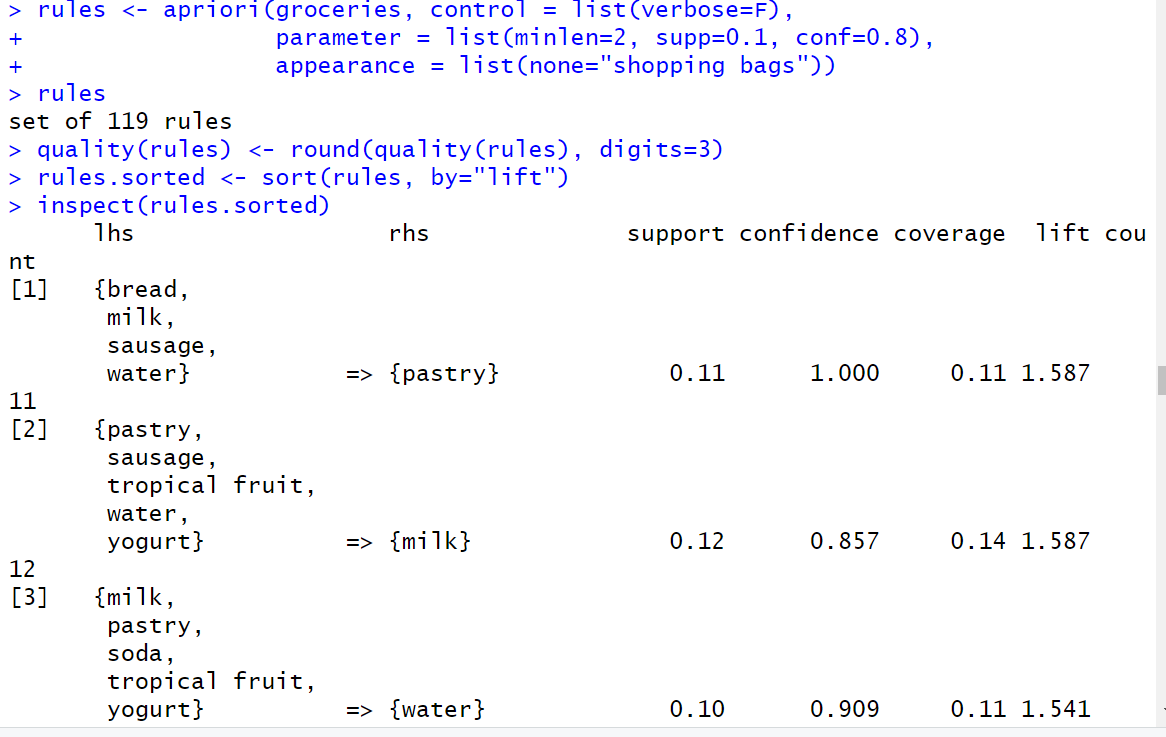
- none = "shopping bags"로 설정
- shopping bags는 다른 데이터와 독립적이므로 연관규칙에서 제외
- 발견된 규칙 중, 의미가 없는 결과들이 많이 포함됨
'빅데이터' 카테고리의 다른 글
| [빅데이터분석] 6장. 분류(2) (0) | 2024.06.08 |
|---|---|
| [빅데이터분석] 5장. 분류(1) (0) | 2024.06.08 |
| [빅데이터분석, Python] 연관 분석 (Assocination Analysis) (0) | 2024.04.21 |
| [빅데이터분석, Python] 전처리(Data-Preprocessing) (0) | 2024.04.21 |
| [빅데이터분석] 4강. 연관 분석 (0) | 2024.04.16 |



