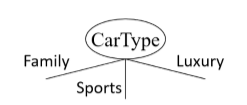
Binary split: Divide values into two subsets; need to find optimal partitioning
ordinal(순서형) 속성에 기반한 분할
Multi-way split
Binary split: Divide values into two subsets; need to find optimal partitioning
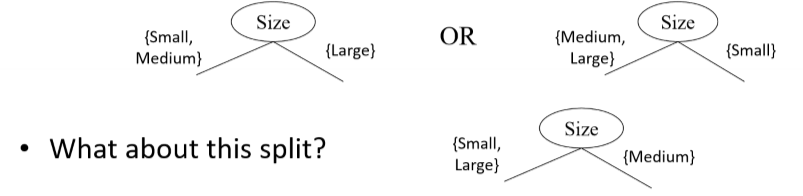
continuous(연속형) 속성에 기반한 분할 threshold가 하나면 binary, 여러 개면 multi-way
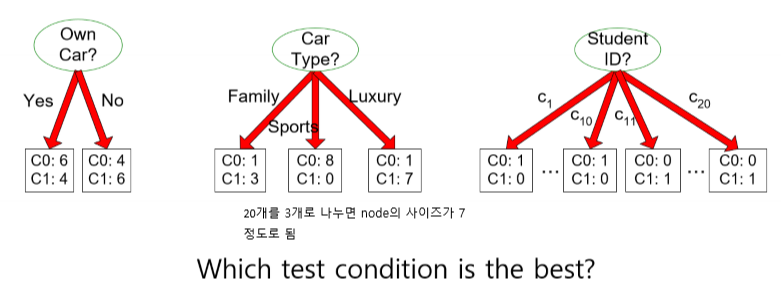
Tree Induction 주요 이슈 - 최선의 분할을 어떻게 결정할 것인가?
Using a greedy approach, nodes with homogeneous class distribution are preferred
Need a measure of node impurity → Measures of Node Impurity node의 size가 크면서 최대한 homogeneous해야 함
Measures of Node Impurity (노드 불순 척도)
Gini Index
Information Gain
Gain Ratio
GINI INDEX
Measure of Impurity: GINI
Gini Index for a given node t: GINI Index 값은 낮을 수록 좋음
Maximum: 노드의 모든 클래스들이 모두 같은 비율로 나누어진 경우 (Maximum when records are equally distributed among all classes, implying least interesting information : Gini = 1 - 1/C)
Minimum (0.0): 노드가 하나의 클래스로만 이루어진 경우 (Minimum when all records belong to one class, implying most interesting information : pi=1, pj=0 (i≠j) → Gini = 0)
Gini 계산 예 C = C1 + C2
GINI 기반의 분할(split)
Used in CART, SLIQ, SPRINT → node impurity를 GINI Index 기반으로 split 하는 알고리즘 (CART: Classfication And Regression Tree 알고리즘. 가장 기본적이면서 classification과 regression모두 적용 가능해서 자주 사용되는 알고리즘)
When a node p is split into k partitions (children), the quality of split is computed as,
A < v and A ≥ v → 2 개의 partition으로 나눔 (v는 threshold)
Simple method to choose best v
For each v, scan the database to gather count matrix and comput its Gini Index
For efficient computation: for each attribute,
Sort the attribute on values
Linearly scan these vlaues, each time updating the count matrix and computing gini index
Choose the split position that has the least gini indx → attribute를 sort 한 후, 선형탐색(Linearly scan)을 통해 최적의 gini index(least)를 구한다.
Information Gain
Entropy(엔트로피)
Entropy at a given node t:
Measures homogeneity of node
Maximum: 노드의 모든 클래스들이 모두 같은 비율로 나누어진 경우 (Maximum when records are equally distributed among all classes, implying least interesting information: log nc (c는 아래첨자))
Minimum (0.0): 노드가 하나의 클래스로만 이루어진 경우 (Minimum when all records belong to one class, implying most interesting information)
Entropy based computations are similar to the GINI index computations
Entropy 계산의 예
Information Gain
Measures the reduction in the entropy caused by the split; choose the split that achives most reduction (maximizes GAIN)
Tree Induction 주요 이슈 - 분할을 언제 멈출 것인가?
트리 유도 중단 기준
모든 레코드가 동일한 class에 속하는 경우 노드 확장 중지
모든 레코드가 유사한 속성 값을 갖는 경우 노드 확장 중지
예외 기준: 의도된 조기 종료
의사결정 트리의 장점과 이슈
decision tree의 장점
모델 형성이 간편하고 빠름
알려지지 않은 레코드를 분류하는데 매우 빠름
작은 규모의 트리는 직관적이며 해석이 가능함
많은 데이터 셋에서 다른 분류 기법과 비교해서 뒤처지지 않는 정확도를 보임
Overfitting (과대 적합)
A model that fits the training data too well can have poorer generalization → training data가 아닌 test data에서는 다른 결과를 보일 수 있음 → 원인: 학습이 너무 되었을 경우, 노이즈로 인한 overfittig
Underfittig (과소 적합)
when a model is too simple, both training and test errors are large → 학습이 덜 되었음
Overfitting 문제 해결: Pre-Pruning
훈련 데이터에 완벽하게 맞는 완전한 트리를 생성하기 전에 트리 생성 알고리즘을 중지시킴
기존 조건보다 더 제한적인 중지 조건을 사용할 필요가 있음
Pre-pruning 기법은 지나치게 복잡한 서브 트리를 생성하는 것을 막을 수 있음
Overfitting 문제 해결: Post-Pruning
일단 의사결정 트리를 최대 크기로 생성하고 완전하게 생성된 트리를 bottom-up 방식으로 trimming함
서브 트리를 리프 노드로 교체하는 방식
특정 값을 기준으로 더 이상 값이 개선 되지 않을 때 종료
Post-pruning은 Pre-pruning 보다 더 좋은 결과를 제공하는 경향이 있지만 pre-pruning에 비해 추가적인 계산이 필요한 단점이 있음
분류 모델의 평가
Confusion Matrix
Accuracy
Limitations of accuracy: C0과 C1이 있다고 했을 때, accuracy could be misleading because this model does not detect any C1. → C0에 대해서는 예측을 잘 하지만, C1에 대해서는 예측을 잘 하지 못하면서 클래스 분균형의 문제가 생김
Sensitivity (true positive rate)
Specificity (true negative rate)
Precision: exactness - what % of tuples that the classifier based as positive are actually positive
Recall: completeness - what % of positive tuples the classifier did label as positive
F measure (F1 or F-score): harmonic mean of precision and recall (종합 평균. Precision과 Recall을 보려고 할 때 사용)
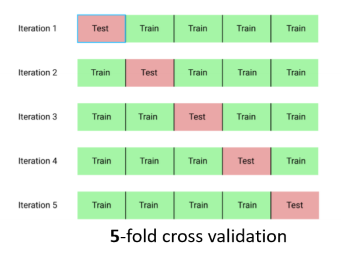
Holdout (홀드아웃) & Cross-Validation (교차검증)
Holdout: The data is randomly paritioned into two independent sets → 데이터를 random하게 training data와 test data 두가지로 구분한 다음, 다시 training data는 training data와 test data로 분할 한다
k-fold cross-validation: Randomly partition the data into K mutually exclusive subsets Di(1≤i ≤k), each approximately equal size → k개의 분할된 data fold set를 만들어 k번 만큼 각 fold set에 training과 test 평가를 반복적으로 수행하는 방법 k=5. 이렇게 testset에 fold를 바꾸어가며 나오는 accuracy들의 평균을 구하면서 성능 평가